Date: June 22nd, 2023
Introduction
Before getting too far into the weeds, let's begin with the results. Without too much effort, an AI was written in clojure that could complete all of the levels in the original Super Mario Bros for the NES except for the Bowser levels that have mazes. Namely, levels 4-4, 7-4, and 8-4 were not completed (more on this later).
Here's what a solved level looks like:
Yup. It's just Mario casually completing the level without any mortal fear and complete disregard for contrivances like mushrooms, coins, or points.
Implementation
The main part of the implementation is the following solve function which we will break down.
(defn solve "Given a `start` state, a distance estimating function, a `successors` function, and a function that says when we're `done`, Try to find a path from the start to the solution." ([start dist successors done?] (solve (priority-map start (dist start)) dist successors done? #{start})) ([queue distf successorsf done? visited] (if (not (Thread/interrupted)) (when-let [[node dist] (with-lookback queue (->coord 1 0 0))] (let [[not-done? dead? below-viewport? xpos speed frames] dist] (swap! stats assoc :queue-count (count queue) :dist dist)) (if (done? dist) node (let [successors (successorsf node) queue (-> queue (into (for [successor successors :when (not (contains? visited successor))] [successor (distf successor)])) (dissoc node)) visited (into visited successors)] (recur queue distf successorsf done? visited)))) {:fail true :queue queue :visited visited})))
There's a few extra steps we'll ignore, but the main steps are:
If we're done, return the result.
Otherwise, choose a node to explore.
Derive new nodes (ie. successors) from the node we picked.
recurback to the beginning and try again.
That's basically it. The only real magic is deciding where to explore. Usually, you want to be "greedy" and just explore closest to your goal, but if you're too greedy, then you might get stuck with no way to continue to greedily move forward.
In this scenario, you need to backtrack to a previous state that does allow you to progress. The node is chosen using the with-lookback function:
(when-let [[node dist] (with-lookback queue (->coord 1 0 0))] ...)
The with-lookback function picks a random distance between 0 and (->coord 1 0 0) , and picks the "best" exploration so far that is at least that many units away from the farthest exploration. What distance does (->coord 1 0 0) represent? I won't cover too much about Super Mario Bros' coordinate system, but (->coord 1 0 0) translates to exactly one screen's distance. Essentially, our algorithm can backtrack up to one screen from our furthest exploration.
Revisiting the levels the AI could not complete (ie. 4-4, 7-4, and 8-4). All of these levels have a maze mechanic where if you go the wrong route, then you will be transported back 4 screens. Since getting transported 4 screens back is beyond the horizon of our backtracking, there's no way our algorithm will ever complete these levels unless they get lucky and choose the correct path on the first try.1
Here's what the process looks like. Below is the sequence of exploring using our solver. You can see each alternate reality explored and how the solver slowly progresses towards the end of the level. It takes a while for Mario to figure out he has to jump up onto each ledge and over the goomba, but he eventually figures it out and proceeds onto the next obstacle.
So yea. The solver is relatively straightforward. Randomly press buttons until you make it to the end of the level. If you get stuck, use save states to backtrack.
It's not super efficient, but it usually doesn't take too long to "solve" a level and it's kinda fun to watch it go. For reference, it takes about two minutes to solve level 1-1. Some of the platforming levels take a bit longer. The two water levels (ie. 2-2, 7-2) have the same layout and take quite a while to solve. Our AI is not a good swimmer.
Successors
Emulating the next state from our current step is pretty straightforward. We generate all combinations of pressing or not pressing the A and B buttons along with all the combinations of pressing left, right, or no direction. For each particular combination, we pick a random number of frames in the range 1-60 (up to one second) to hold this configuration and then simulate the result. It's important for our successor function to generate button presses for several frames because a common platforming action is long jumping (ie. holding the jump button for a full jump). If successor states were generated for each frame, then the common action of holding the jump button for a few seconds is extremely unlikely.
While it's possible for Mario to enter a pipe by pressing down, we ignore that for our purposes. I'm not sure the up button has any use in Super Mario Bros so we also ignore that button when generating successor states.
Below is the code for generating the successor states with some debug code elided for brevity.
(def buttons [:RETRO_DEVICE_ID_JOYPAD_A :RETRO_DEVICE_ID_JOYPAD_B]) (def directions [:RETRO_DEVICE_ID_JOYPAD_LEFT :RETRO_DEVICE_ID_JOYPAD_RIGHT nil]) (defn ^:private next-state "Given a sequence of past inputs, run the current game for `num-frames` with `controls` inputs set." [inputs controls num-frames] (let [state (get @state-cache inputs)] (assert state) (load-state state)) (with-redefs [input-state-callback (fn [port device index id] (if (controls (c/device-name id)) 1 0))] (dotimes [i num-frames] (retro/retro_run))) (let [new-state (get-state) new-inputs (conj inputs {:controls controls :num-frames num-frames})] (swap! state-cache assoc new-inputs new-state) new-inputs)) (defn successors "Generates successor states given past inputs." [inputs] (into [] (comp (map (fn [[buttons dir]] (set (if dir (conj buttons dir) buttons)))) (map (fn [controls] (next-state inputs controls (inc (rand-int 60)))))) (combo/cartesian-product (combo/subsets buttons) directions)))
Distance
The solver accepts a dist function that should return a comparable heuristic value. For our implementation, it doesn't matter what the heuristic returns as long as it can be compared against other values returned from dist.
(defn dist "Checks the current RAM and estimates the current distance from the goal." [inputs] (let [save-state (get @state-cache inputs)] (retro/retro_unserialize save-state (alength save-state))) (let [mem (retro/retro_get_memory_data RETRO_MEMORY_SYSTEM_RAM) screen-tile (.getByte mem 0x006D) xpos (.getByte mem 0x0086) subpixel (.getByte mem 0x0400) ;; absolute speed (.getByte mem 0x0700) vertical-position (.getByte mem 0x00B5) below-viewport? (> vertical-position 1) on-flag-pole? (= 0x03 (.getByte mem 0x001D)) dead? (= 3 (.getByte mem 0x0770)) ypos (byte-format (.getByte mem 0x03B8))] [(not on-flag-pole?) dead? below-viewport? (- (->coord screen-tile xpos subpixel)) ypos (- speed) (count inputs)]))
The 7 main factors of our current heuristic are:
(not on-flag-pole?): Indicates whether we've reached our final goal, the flag pole!dead?: Indicates whether Mario has died.below-viewport?: One of Mario's primary hazards is falling into bottomless pits. Mario doesn't die instantly when he falls in a pit. This heuristic let's us short circuit when we know Mario is falling to his doom.(- (->coord screen-tile xpos subpixel)): Measures Mario's horizontal position. The value is negated becausedistshould decrease as we get closer to our goal.ypos: Mario's vertical position. Since it's easier for Mario to fall than to climb, we prefer exploring states where Mario is higher up. There are scenarios where this heuristic could get us stuck, but it didn't seem to be a problem for the levels we explored. Overall, this heuristic was very helpful for making it through the platforming levels with many bottomless pits. This value is not negated because it's already measured from the top of the screen and decreases as it "improves".(- speed): Mario's absolute horizontal speed. We prefer fast Mario over slow Mario. Negated becausedistshould decrease as we get closer to our goal.(count inputs): This is the total number of different steps we've taken in our current path. We penalize longer paths.
Levels
Here are the completed levels. As you can see, the AI does not play like a normal human, but is definitely not super human either (yet!).
Note: Some levels will look very similar to other levels. I promise I didn't upload the wrong video. Notably, world 7 copies heavily from world 2.
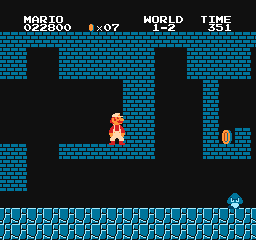
Level 1-1
Level 1-2
Level 1-3
Level 1-4
Level 2-1
Level 2-2
Level 2-3
Level 2-4
Level 3-1
Level 3-2
Level 3-3
Level 3-4
Level 4-1
Level 4-2
Level 4-3
Level 5-1
Level 5-2
Level 5-3
Level 5-4
Level 6-1
Level 6-2
Level 6-3
Level 6-4
Level 7-1
Level 7-2
Level 7-3
Level 8-1
Level 8-2
Level 8-3
Conclusion
Overall, I'm pretty happy that this simple AI was able to beat all the non maze levels. There's also plenty of room for improvement to explore in the future.
Future Work
Generalize
There's a lot of hard-coded pieces. It would be nice to refactor to make it easier to support more exploration strategies, heuristics, and policies.
Improved Exploration and Backtracking
Currently, the solver will only backtrack based on horizontal position. Furthermore, the backtracking window is constant. There are multiple theoretical improvements, but one general idea is to continue being greedier when you're making progress and spend more time exploring when you get stuck. With a better exploration strategy, maybe our solver could be improved to beat the dreaded maze levels.
Beating the Full Game
In addition to not being able to complete some of the Bowser levels, our solver also doesn't handle pipes and level transitions well. It shouldn't be that hard to detect those cases so that the solver can solve multiple levels and eventually, the full game.
Extra Resources
All code for this project can be found on github.
Tom7's learnfun & playfun: A general technique for automating NES games
Agent57: Outperforming the human Atari benchmark
Reinforcement Learning and DQN, learning to play from pixels